
Cyber Resilience: Why Annual DR Tests Are Not Enough and What Actually Works





After more than twenty years in cyber security, one thing has remained remarkably consistent. Complacency around resilience.
I have lost count of the number of times I have heard phrases like “we test disaster recovery every year”, “it will never happen to us”, or “we have backups so we will be fine”.
These statements are usually made with confidence. They are also usually wrong.
Resilience is not about whether you have a plan. It is about whether that plan works under pressure, reflects how the business actually operates, and can be executed when things are already going badly.
This article looks at why resilience so often fails in practice, how to get meaningful business buy-in before an incident occurs, and what we have seen work in the real world.
Why Annual DR Tests Do Not Mean You Are Resilient
An annual disaster recovery test is better than no test at all, but it is a long way from proving resilience.
In many organisations, these tests are highly controlled, predictable, and disconnected from reality. They are often run by the same people, at the same time each year, with the same assumptions baked in.
Common issues include:
- Tests that only cover infrastructure, not end-to-end services
- Known issues being worked around rather than fixed
- Success being declared without independent challenge
- No senior decision makers involved
- Findings documented but never tracked to completion
Resilience fails not because teams are careless, but because testing is treated as a compliance activity rather than a learning exercise.
“It Will Never Happen to Us” and Other Dangerous Assumptions
One of the hardest challenges is persuading the wider business to take resilience seriously.
Security and technology teams often understand the risks. The difficulty is translating those risks into something the business cares about before an incident forces the issue.
Common pushback sounds like this:
- We are not a target
- We have never had a major incident
- We have backups
- We cannot afford to spend time on this
Unfortunately, many high-profile incidents started in organisations that believed exactly the same things.
Resilience is not about predicting the exact scenario that will occur. It is about accepting that disruption will happen in some form and being ready to respond.
How to Get Business Buy-In Without Waiting for a Crisis
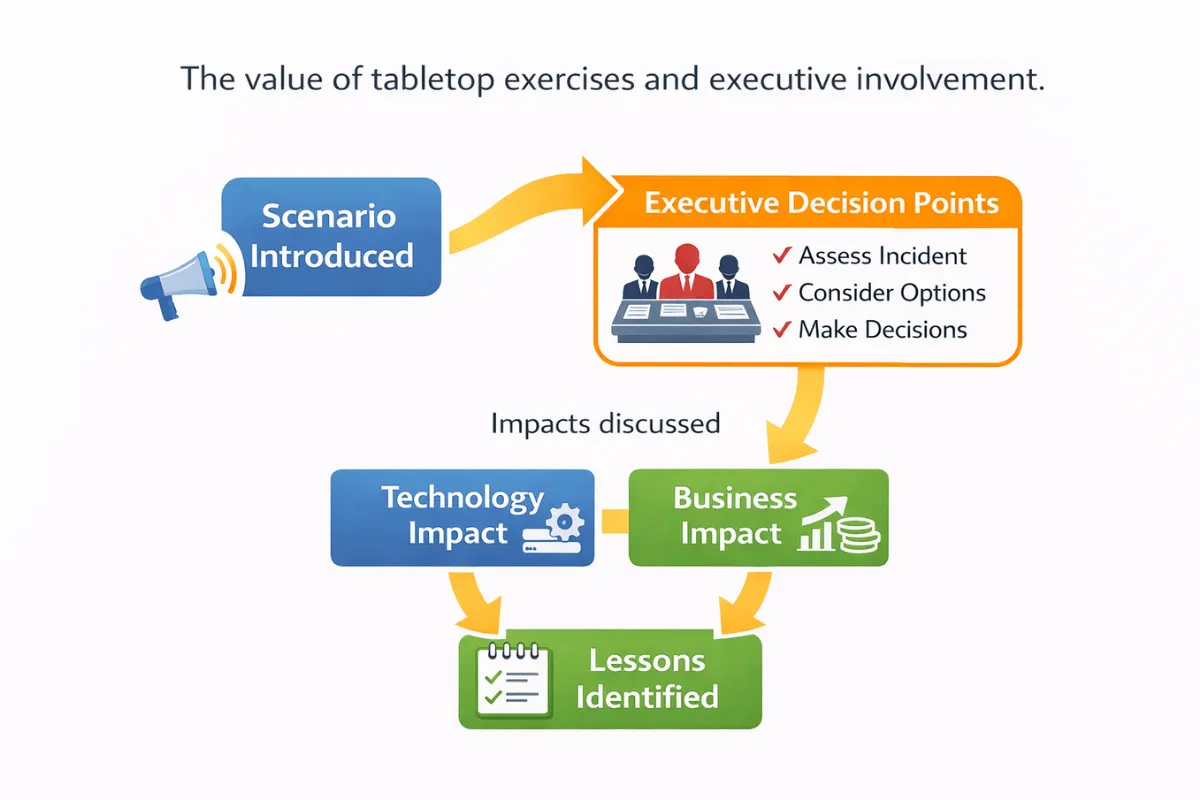
The most effective way to raise the profile of resilience is not another document or risk register.
It is involvement.
What we have consistently seen work is the use of tabletop exercises with senior leaders. These are structured, discussion-based sessions that walk through a realistic disruption scenario and force decisions to be made.
Tabletop exercises help to:
- Expose unclear decision making authority
- Highlight gaps between technical recovery and business expectations
- Reveal unknown dependencies on people or suppliers
- Create shared understanding across teams
- Surface issues in a cost-effective way
When executives experience these challenges first-hand, resilience stops being an abstract concept and becomes a business issue.
Testing More Often and Testing the Right Things
Another common mistake is leaving a full year between tests. Systems change constantly. Cloud providers add and remove features. Configurations drift. People move roles or leave the organisation.
If recovery procedures are not tested regularly, they quickly become outdated.
A more effective approach is layered testing:
- Regular tabletop exercises with senior stakeholders
- Quarterly or monthly technical recovery tests for critical systems
- Focused tests after significant changes or incidents
These shorter, more frequent tests are far more effective at maintaining confidence and catching issues early.
Documenting Tests So Issues Do Not Disappear

Running tests is only half the job.
If issues identified during exercises or recovery tests are not documented, tracked, and resolved, resilience does not improve.
Good practice includes:
- Recording findings in your incident or support system
- Assigning clear ownership for each issue
- Tracking progress to resolution
- Retesting to confirm fixes are effective
This creates evidence that resilience is actively managed rather than assumed.
Is Your Recovery Time Objective Actually Realistic?
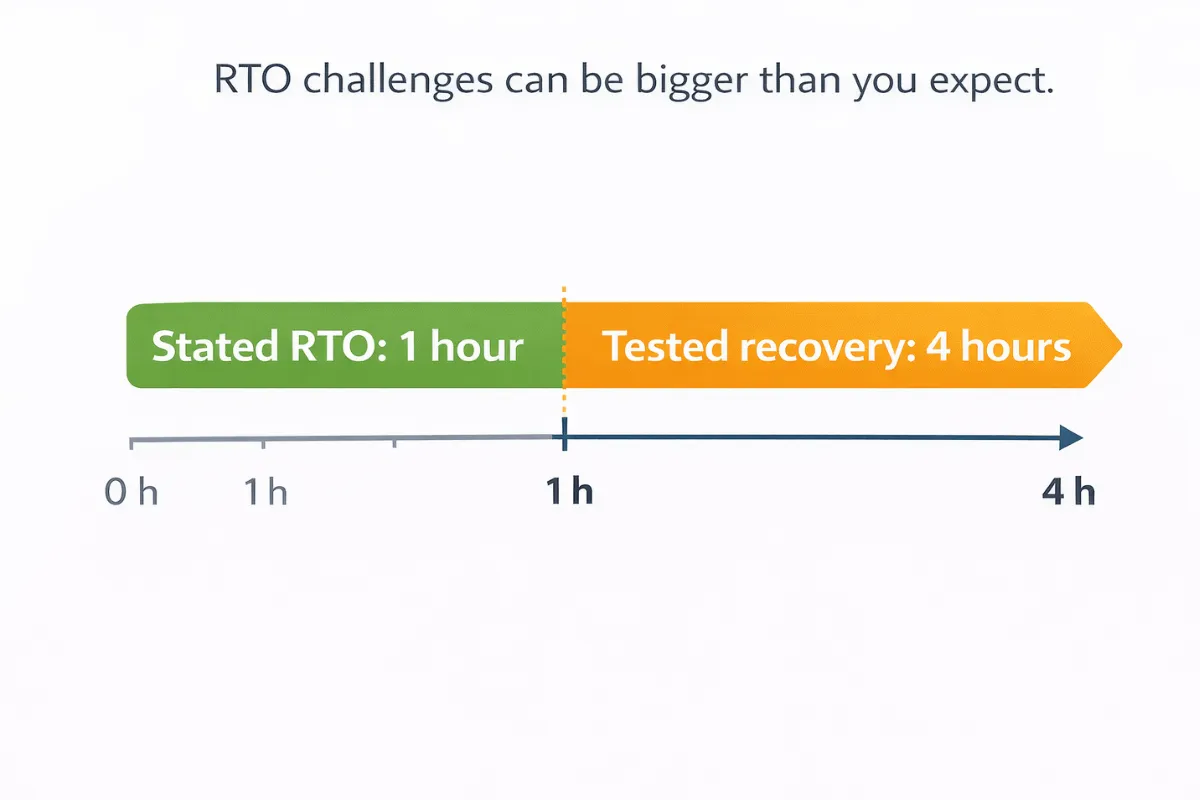
Recovery Time Objectives are often optimistic.
It is easy to state that a service can be recovered within one hour. It is much harder to demonstrate that this is achievable under realistic conditions.
We regularly see situations where:
- Stated RTOs are driven by aspiration rather than evidence
- Tests take significantly longer than documented objectives
- Dependencies are discovered during recovery rather than planned for
- Manual steps add unexpected delays
- This is where a proper business impact analysis is critical.
Focus on your important business services, not just individual systems. Understand what recovery actually involves and adjust RTOs accordingly.
If you cannot meet a stated RTO, that is not a failure. The failure is pretending otherwise.
Making Risk-Based Decisions Before an Incident Occurs
Once gaps are identified, the business has a choice. It can invest to improve recovery capability, or it can formally accept the risk.
What matters is that this decision is made consciously, documented, and owned at the appropriate level.
This approach is important for two reasons:
- It ensures senior leaders understand the trade-offs
- It demonstrates to regulators that risks were assessed and managed appropriately before an incident
Risk acceptance is a valid outcome when it is informed and documented. Wishful thinking is not.
Common Resilience Mistakes We See Repeatedly
- Assuming backups equal recovery
- Treating resilience as a technology problem only
- Testing too infrequently
- Excluding senior decision makers from exercises
- Setting unrealistic recovery objectives
- Failing to track and resolve known issues
These mistakes are common because resilience is uncomfortable. It exposes weaknesses that are easy to ignore until something goes wrong.
Frequently Asked Questions
We test disaster recovery every year. Is that not enough?
It is a good start, but resilience requires more frequent and realistic testing, including decision making and business impact.
How do we make the business take this seriously?
Involve them directly through tabletop exercises and realistic scenarios that relate to important business services.
Do regulators expect this level of resilience?
Increasingly, yes. Regulators focus on whether organisations understand their risks and can recover critical services, not just whether plans exist.
Conclusion
Resilience is not proven by having plans or policies. It is proven by what happens when those plans are tested and when assumptions are challenged. Organisations that invest time in realistic testing, honest assessment, and documented decision making are far better placed to respond when disruption occurs.
The goal is not to eliminate incidents. It is to ensure they do not become crises.
How Onion Security Helps
This is often the point where organisations realise resilience gaps are not caused by missing tools, but by missing clarity. Onion Security helps organisations test their assumptions, involve the right people, and turn resilience from a yearly obligation into a practical capability.
The focus is on making resilience realistic, proportionate, and defensible, so that when something does go wrong, the organisation is ready.



Your Trusted Partner



